
Visual ChatGPT перетворює текст в зображення

Дослідники Microsoft нещодавно опублікували статтю , спрямовану на об’єднання можливостей ChatGPT і візуальних базових моделей, таких як Stable Diffusion. Ця архітектура під назвою «Visual ChatGPT» має на меті подолати розрив між перетворенням тексту в зображення та створенням природної мови.
Як передбачав AIM , це, здається, шлях вперед для алгоритмів перетворення тексту в зображення . Цей підхід поєднує в собі сильні сторони LLM, як-от ChatGPT, із потужністю генерації зображень, надаючи комплексний пакет, який покриває недоліки обох цих платформ. Переносячи обробку природної мови в моделі генерації зображень на основі параметрів, можна більш органічно взаємодіяти зі ШІ .
Як працює Visual ChatGPT?
Простіше кажучи, демонстрація додає можливості обміну зображеннями за допомогою ChatGPT. Ця функція досягається за допомогою «менеджера підказок» для обміну інформацією між різними моделями візуальної основи, такими як Stable Diffusion , ControlNet, BLIP і ChatGPT.
Менеджер підказок взаємодіє між ChatGPT і цими VFM для безпроблемної обробки вихідних даних. Для прикладу візьмемо кухню ресторану. У той час як ChatGPT схожий на офіціанта, який приймає замовлення клієнтів, VFM схожий на шеф-кухаря на кухні, який готує страву. Оперативний менеджер бере на себе роль керівника кухні, передає замовлення та їжу між офіціантами та кухарями.
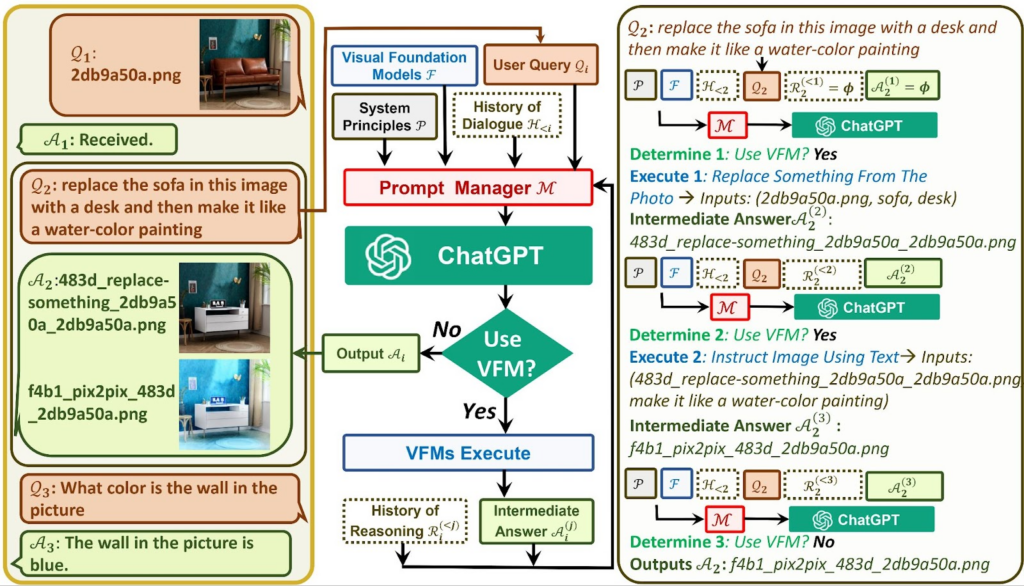
Таким чином, диспетчер підказок включає певну логіку, наприклад формат міркування, який допомагає ChatGPT вирішити, чи потрібно використовувати інструмент (наприклад, VFM), щоб надати необхідний результат. PM також піклується про ітераційні міркування, які використовуються для точного налаштування вихідного зображення. Він також займається певним обслуговуванням, наприклад керуванням іменами файлів у виводі ChatGPT і відстеженням імен файлів зображень.
Менеджер підказок справді є серцевиною цієї системи, оскільки саме його використовує ChatGPT, щоб відповісти на будь-який тип немовних запитів. У певному сенсі менеджер підказок заступає користувача, переміщуючи ChatGPT до необхідного результату за допомогою серії налаштованих підказок. Це призводить до набагато більш потужної версії ChatGPT, яка не покладається на галюцинації, натомість змушена використовувати можливості VFM через диспетчер підказок.
Хоча Visual ChatGPT здатний сам по собі, він створює прецедент, який є більш захоплюючим. Чи можливо об’єднати неймовірні можливості LLM і візуальних моделей, і чи може це бути одним із перших кроків до AGI?
Зміна вигляду тексту в зображення
Існує фундаментальна проблема з тим, як працюють моделі перетворення тексту в зображення, і це нерозуміння лінгвістичного контексту. У статті , присвяченій реляційному розуміння генеративних моделей штучного інтелекту, дослідники виявили, що ці моделі не «розуміють» фізичні зв’язки певних об’єктів.
Наприклад, хоча модель була здатна створити зображення для «дитини, яка торкається миски», вона не могла створити зображення «мавпи, яка торкалася ігуани». Це пояснюється тим, що в навчальних даних останнього сценарію недостатньо інформації, що призводить до неадекватних відповідей. Щоб подолати це обмеження моделей перетворення тексту в зображення, з’явилася нова робота — шепоти ШІ або оперативне проектування .
Процес, за допомогою якого моделі штучного інтелекту «розуміють» людей, досі залишається незвіданою територією, яку повільно окреслюють перспективні художники ШІ. Ось чому у нас є такі веб-сайти, як «PromptHero», сховище підказок для алгоритмів перетворення тексту в зображення, які просто працюють, і ось чому, здавалося б, безглуздий суп слів може надати приголомшливі зображення ШІ. Розглянемо наведений нижче приклад .
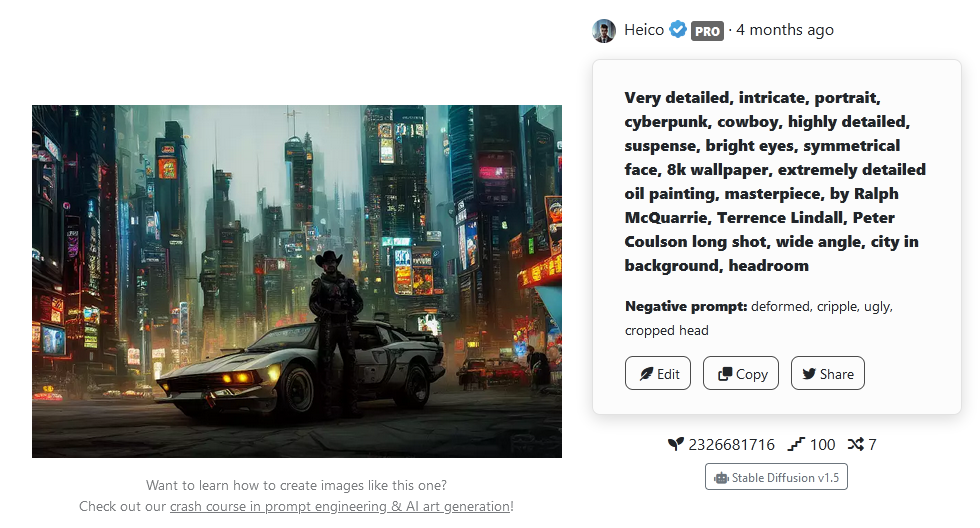
Як видно на цьому зображенні, отримання надійних результатів із моделі перетворення тексту в зображення вимагає комплексної бази знань про те, що запитувати. Негативні підказки також використовуються, щоб уникнути певних характеристик у завершеному зображенні. Дивлячись на те, в якому напрямку береться оперативно-менеджер Microsoft, здається, що потенціал для цієї роботи вичерпано ще до її початку.
З прикладів, наведених на сторінці GitHub , стає зрозуміло, що користувачам не потрібно брати участь у таких складних підказках, щоб передати інформацію моделі. Вони можуть просто ввести природною мовою те, що хочуть від моделі. Наприклад, після створення зображення кота користувач просить ChatGPT замінити кота собакою. Зображення було створено без будь-яких складних підказок, і користувач неодноразово вносив до нього зміни, наприклад змінював колір.
Такі інструменти, як Visual ChatGPT, можуть не тільки зменшити бар’єр входу до моделей тексту в зображення, але також можуть використовуватися для додавання сумісності з різними інструментами ШІ. Раніше моделі LLM і T2I існували окремо, але завдяки таким технологіям, як менеджер підказок, ми могли б розширити можливості цих найсучасніших моделей.






