
Пародійний чат-бот із 1960-х років перевершив GPT-3.5 у тесті Тюрінга 3.6

Чат-бот “Еліза”, написаний 1966 року, у розмові з людьми зміг краще переконати їх у тому, що є людиною, ніж чат-бот GPT-3.5, який створили 2022-го. Автори нового дослідження зазначили, що тест Тюрінга, який багато фахівців вважають золотим стандартом оцінки здібностей штучного інтелекту, може бути неточним.
Британський математик і криптограф Алан Тьюринг колись задався питанням, чи може машина мислити і поводитися в розмові з людьми як людина. Міркування на цю тему привели його в 1950 році до створення відомого тесту. Сьогодні його використовують для того, щоб визначити вміння чат-ботів прикидатися людиною.
Виглядає цей тест так. Користувач через спеціальну програму спілкується з одним комп’ютером і однією людиною. При цьому він не знає, хто є хто. На підставі відповідей на запитання необхідно визначити, з ким розмовляє випробовуваний: з людиною чи чат-ботом. Завдання машини – ввести в оману, змусити зробити неправильний вибір.
Якщо протягом певного часу “піддослідний” не може відрізнити програму від людини, вважається, що машина успішно завершила тест. Однак багато фахівців називають цей тест суб’єктивним, адже досі немає єдиної думки про те, що необхідно вважати показником успішного його складання.
Ще більше негараздів у це питання внесли дослідники з Каліфорнійського університету в Сан-Дієго (США). Вони створили спеціальний сайт, за допомогою якого провели онлайн-тест Тюрінга. Завданням було дізнатися, який зі “співрозмовників” краще за інших видасть себе за людину: моделі штучного інтелекту GPT-4, GPT-3.5, “Еліза” (ELIZA) або група людей. Результати роботи опубліковано на сайті електронного архіву препринтів arXiv.
Загалом в експерименті брали участь 652 людини. Через сайт під час більш ніж тисячі сесій вони взаємодіяли з трьома моделями штучного інтелекту (GPT-4, GPT-3.5, “Еліза”) або іншими людьми. Після чого випробовувані мали повідомити, з ким спілкувалися: людиною чи чат-ботом.
Дослідження показало, що людей “по той бік екрана” учасники експерименту правильно визначили в 63 відсотках випадків, а в 37 відсотках вважали їх ботами. Моделі GPT-4 і GPT-3.5 переконували випробовуваних, що ті спілкуються з людиною в 41 і 14 відсотках випадків відповідно. Найбільше вчених здивував “дідок” – чат-бот “Еліза”, створений 1966 року американським ученим Джозефом Вейценбаумом (Joseph Weizenbaum) для пародіювання спілкування психоаналітика з клієнтами. Показник успішності цієї мовної моделі становив 27 відсотків, тобто набагато вищий, ніж у “молодої” GPT-3.5, чого аж ніяк не розраховували побачити вчені.
Успіх “Елізи” автори статті пояснили трьома причинами:
- відповіді цього чат-бота, як правило, були консервативними, що створювало враження “незговірливого співрозмовника”. Така “поведінка” дозволила не викрити систему. “Еліза” зводила до мінімуму видачу невірної інформації;
- “Еліза” не показувала тих якостей, з якими користувачі звикли асоціювати сучасні мовні моделі, як-от послужливість, дружелюбність і багатослівність;
- “Випробовувані” повідомили, що чат-бот “надто поганий, щоб бути схожим на модель штучного інтелекту”, тому, найімовірніше, з ним спілкувалася людина.
Під час сеансів учасники експерименту вели світські бесіди зі “співрозмовниками”, цікавилися їхніми знаннями та думками про актуальні події. Крім того, спілкувалися іноземною мовою і доволі часто звинувачували в тому, що вони модель штучного інтелекту, тобто “тиснули на психіку”.
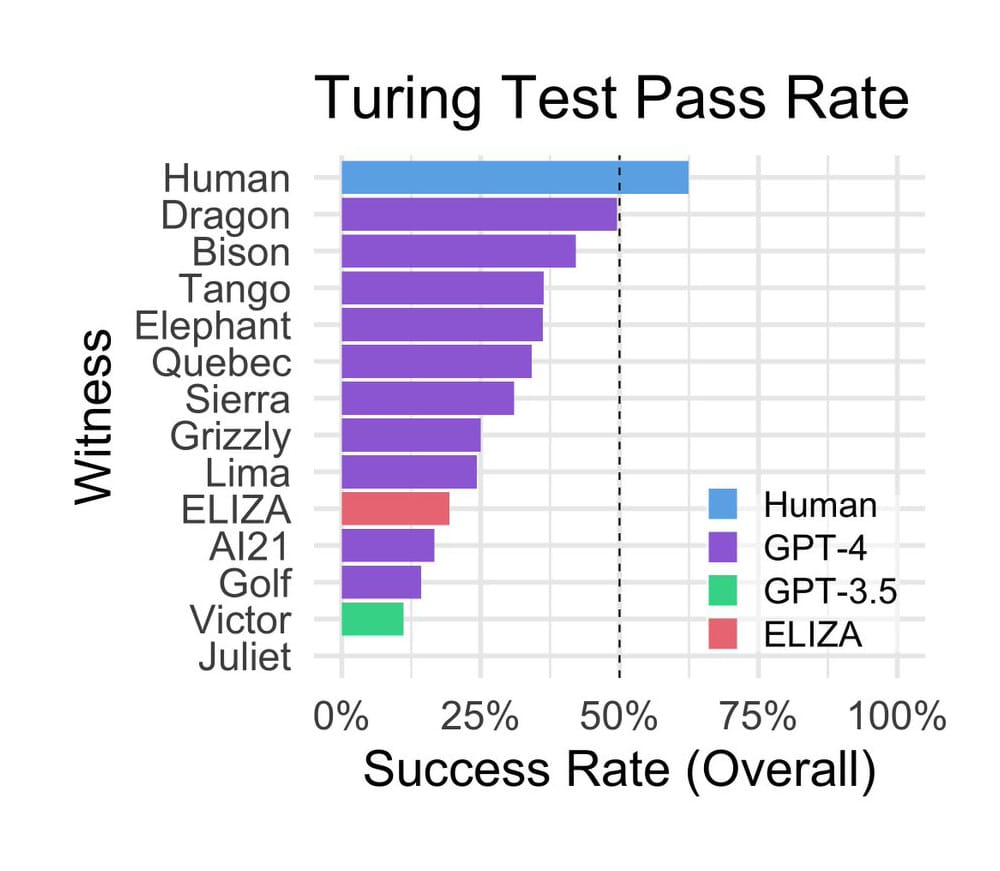
Гістограма успішності виконання тесту Тюрінга, проведеного американськими вченими / © Cameron Jones
Піддослідні ухвалювали рішення про те, спілкувалася з ними людина чи чат-бот, насамперед на основі манери спілкування та емоційних рис “співрозмовника”, а не тільки на сприйнятті їхнього рівня інтелекту. Також користувачі відзначали, коли відповіді на їхні запитання були надто формальними або неформальними, коли відповідям бракувало індивідуальності або вони здавалися узагальненими.
Автори визнали деякі недоліки свого дослідження. Зокрема, занадто малу вибірку та відсутність стимулів для учасників, що, можливо, вплинуло на їхні відповіді – ймовірно, вони не були щирими.
Також учені зазначили, що результати їхньої роботи якоюсь мірою показали неспроможність тесту Тюрінга, особливо якщо брати до уваги продуктивність “Елізи”. Тобто цей тест може бути неточним в оцінці здібностей штучного інтелекту. Модель “Еліза” гіпотетично мала впоратися гірше із завданням, ніж GPT-3.5. Дослідники підкреслили: їхні висновки не означають, що від тесту потрібно терміново відмовлятися. Він, як і раніше, актуальний і цілком життєздатний.
Що стосується GPT-3.5 – це базова модель, безкоштовна версія ChatGPT. Команда OpenAI спеціально розробляла її для того, щоб та не видавала себе за людину. Це може хоча б частково пояснити її низьку результативність в експерименті.






